Master Schema Extension Good Practice Guide
Introduction
The Mydex Master Data Schema is a person-centric data model designed to be extensible to cover any and every aspect of a persons life over their whole lifetime. This is the data model used to support the Mydex Personal Data Store (PDS) platform.
The purpose of this good practice guide is to:
- explain the rationale behind the structure of the Master Data Schema;
- show how easily it can be extended to cover other use cases outside of the current system;
- facilitate community engagement with its ongoing extension and development;
- set out the recommended approach for extending the schema;
- give some worked examples of creating additional fields within the schema.
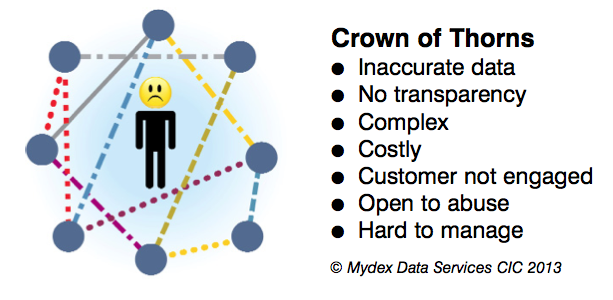
The critical point here is that it is person-centric - it does not take the standpoint of any particular Subscribing organisation, whether they be companies, charities or even standards organisations. If you look at the use of your personal data by Subscribing organisations you will soon see that there are bits of data scattered across all of the Subscribing organisations you have dealings with, with nobody having a complete picture - not even you. These Subscribing organisations may communicate amongst themselves or with you, but the complex arrangements can lead to inaccurate data and be hard to manage. This can be thought of as a ‘crown of thorns’, as shown in the diagram below.
The alternative approach is person-centric, putting the individual the centre of the web of data connections and firmly back in control. As the individual is now responsible for their own data and is able to share this with Subscriber organisations, the accuracy and completeness of the data improves and a greater degree of trust can be attained between the parties. This is shown in the ‘halo of trust’ diagram below.

The Mydex PDS provides the platform for individuals to create the halo of trust with the Subscribing organisations they deal with. This is explained in detail in the Mydex Charter and the Privacy Policy, but in summary the platform provides the individual with:
- A secure area for the storage and management of their personal data. This is unique to them and nobody else can gain access to this data, not even Mydex;
- The ability to securely connect to the Subscribing organisations they have dealings with in order to maintain an ongoing relationship;
- The tools to be able to consolidate, view, analyse and manage their data.
Schema Structure
Behind the PDS lies the data model which supports the storage and manipulation of all of the personal data fields. This is termed the Mydex Master Data Schema.
When we started designing the Mydex schema, there were a number of design constraints we imposed upon ourselves in order to make life simpler:
- The schema, first and foremost, must be person-centric, i.e. to allow the individual to record all aspects of their digital life.
- The design of the schema should incorporate best practice wherever possible. Where we find a publicly available schema for a particular use case, we may adopt the person-centric parts of the schema for inclusion within the schema.
- The schema is not designed to provide support to any particular Subscribing organisations.
- The schema should be open, easily extendible and simple to use.
The schema is structured as a series of flat ‘tables’ with each table corresponding to a dataset, which together form a very shallow hierarchy. Considering the example of a bank account where there is a top level dataset holding the metadata about the account (called ds_bank_account) and an associated transaction dataset (called ds_bank_account_transactions).
The Mydex Master Schema is published openly and accessible to all. Details of the datasets available on this documentation site, under Data Schema. Access to the data within the datasets is via API calls, which provide a simple mechanism for reading from and writing to the PDS. Again, details can be found on this site under Personal Data eXchange API.
Schema Policy
The approach adopted for the design and use of the schema has deliberately been kept as simple as possible in order for developers to concentrate on developing apps to work with the data rather than having to understand complex data structures associated with their data. All extensions to the existing schema will need to conform to this ‘keep it a simple as possible, but no simpler’ approach.
In addition, there are a number of ‘rules’ which are designed to ensure that all of the fields within the schema are consistent and easily identified.
Permitted Data
While there are many things which could be stored within the PDS, there are a few types of data which we do not store on the Mydex platform. For example, we do not wish to store blob files, such as videos, images, sounds or other multimedia files as:
These files are likely to be large and therefore will take up an increasing amount of storage and bandwidth. There are plenty of other Subscribing organisations which can provide storage for these types of objects and we feel it is better we support their use these storage services and focus on storing the meta-data around these types of objects and providing a centralised management of permissions and consent for access to them.
There are other considerations here for us as a community Interest Company a Trust Framework operator and a certified ISO27001and Fair Data company. These can be summarised as:
- We do not charge individuals for the services we provide to them and would not realistically be able to support an opened storage and network bandwidth commitment for high volumes of large objects. data itself is relatively small by comparison.
- Over time our members may choose to locate their core Personal Data Store wherever they wish and therefore support for federated data sources is fundamental to this vision as is specialised data and streaming services providers, not everything needs to be encrypted, it is more important for us to provide the framework for permission and consent management to wrap around this type of content.
The table below shows a number of different data types and list what can and cannot be stored within the PDS schema.
| Data Type | What we will not store | What can be stored |
|---|---|---|
| character | Any single character | |
| currency | Any currency value | |
| date | Any date value | |
| number | Any numeric value (integer or real) | |
| text | Any text string | |
| time | Any time value | |
| pointers and references | Pointers to external web sites Meta data describing the pointer | |
| videos | any video files | Pointers to the site where the video is stored Meta data about the video, such as the date, time and location that it was taken, a description of the video etc. |
| images | any image files save those used as part of their profile | Pointer to the site where the image is stored Meta data about the image |
| sounds | any audio or music files | Pointers to the site where the sound is stored Meta data about the sound |
| encrypted files | any files which have been encrypted | Any files digitally signed as part of a certified connection to underpin verified data |
| pdf files | pdf files generated by the individual | pdf files generated by a trusted connection (e.g. bank) |
In addition, there are data on certain topics that we would not wish to be stored within the PDS schema. These are likely to be non personal or non personal-related data, such as reference data or general descriptions. As a general rule:
- If the individual cannot be thought of as the owner/custodian/curator of the data then it should not be included within the PDS. Instead, a pointer should be included to the relevant source.
- If the information is not needed as part of the developers application, then it should not be included within the PDS.
- If, as part of a developer’s application, it is necessary to have access to information which may change over time, and there is no definitive online source to point to, then the data may be stored in the PDS. An example might be the Terms & Conditions for an insurance policy, which would vary from year to year.
Naming Convention
All new datasets and fields added to the schema will need to conform to the naming convention summarised below:
Master Data Schema Version 1 Naming convention
The value in red is constant throughout the Master Schema the value in blue represents the dataset name.
| Name | Dataset Name | Description | Environment |
|---|---|---|---|
| Bank Account | ds_bank_account |
Details of a member's bank account | Production |
| Credit Card | ds_credit_card |
Details of the member's credit cards. | Production |
| Driving Licence | ds_driving_licence |
Data relating to a members driving licence | Production |
| Education | ds_education |
Data relating to a members education history | Production |
| Employer | ds_employment |
Details of each employer. | Production |
| Health | ds_health |
High-level health and GP details. | Production |
The value in red represent the constant within the dataset itself, the value in blue is the field name itself within the dataset.
Dataset name:ds_employment
Description
Details of each employer
Fields in this dataset
| Name | Field Name | Description | Field Type |
|---|---|---|---|
| Employee ID | field_emp_employee_id |
The member's employee ID | text |
| Employer Name | field_emp_employer_name |
The name of the member's employer | text |
| End Date | field_emp_end_date |
The member's end date of employment | date |
| Job Title | field_emp_job_title |
The member's job title | text |
| Salary | field_emp_salary |
The member's salary | number |
| Start Date | field_emp_start_date |
The member's start date of employment | date |
Master Data Schema Version 2 Naming convention
Following review and feedback we have been developing a new simpler naming convention. We will maintain backward compatibility through use of a synonym table when it is implemented.
| Type | Version 1 | Version 2 |
|---|---|---|
| Dataset | ds_dataset_name | dataset_name |
| Field | field_[abbreviated dataset name]_field_name | attribute_name |
It is cleaner, it will make life easier for all developers and it will be more easily extensible as we provide API helper functions that deliver results back from requests for answers as opposed to pure data e.g. requests about status, age on a given day, entitlement etc. these types of enquiries will have a series of parameters and may perform complex enquiries across multiple datasets but be accessed via a simple API call.
Data Formats
In order for all data to be consistent data of a particular type should conform to specific formats, as detailed below. All data stored within the PDS uses the UTF-8 character set.
| Data Type | Format | Notes |
|---|---|---|
| character | Any single character | E.g. 'Y' or 'N' |
| currency | Any numeric value | Currency values also have an associated currency code which identifies the specific format. |
| date | Unix Timestamp | |
| meta data | No particular format, but made up of a number of fields of other data types, e.g. date, time, text. | As specified by the particular data types used |
| number | Real or integer number | |
| pointer | A string of characters | It may be part of the developer;s application to ensure the validity of a URL |
| text | A string of characters without length restrictions. | |
| Time | Unix Timestamp |
Reference Data
There are a number of areas where reference data has been included within the PDS schema. Examples of these occur in the system where there are drop-down menus to provide users with a limited set of options, such as the name of a country in a group of address fields. Wherever possible, we have used an existing standard, such as ISO 3166 for country names or ISO 4217 for currency codes, or failing this we have used best practice.
Developers should consider the use of this sort of reference data when requesting additional datasets and fields to be added to the schema, but will need to indicate the source of the reference data so that the list within the PDS can be maintained.
Making extensions to the schema
New datasets to cover new use-cases are constantly being added to the platform by Mydex. These start out on the Sandbox environment where they are thoroughly tested before graduating to the live platform.
As well as this, it is anticipated that others may also have in mind particular use cases which are not currently catered for within the PDS. These use cases are likely to require additions to the schema in order to support them, so we have made it easy for others to contribute to the extension of the schema, by proposing use-cases and associated fields of their own.
Preparatory Work
In order to decide what datasets and fields are to be add to the schema, a data modeller / developer will need to carry out some preparatory work. This is likely to be carried out as part of their analysis in any case, but is listed here for clarity.
The data modeller / developer will need to:
- research within the domain area in order to establish:
- are there any open standards which have been developed in the domain area?
- if there are no open standards, are there any de facto standards?
- are there any emerging trends?
Many of the schemas that exist for various business areas have been developed from the standpoint of the Subscribing organisations that will use them. The PDS has a different view - that of the individual.
As an example, vehicle insurance will include details of the correspondence address (i.e. the address of the individual), whereas the individual knows where they live and whilst it is important to make sure that the insurer has the correct address the individual is also interested in the contact details of the insurance company.
In short, imagine that you are trying to catalog the data about yourself for your own personal use rather than for the benefit of an Subscribing organisation. This usually exposes additional datasets that are needed, the sorts of things that normally go on the letterhead or the template of documents posted, PDF’s generated or emails sent.
- consider which of the datasets and attributes you will be delivering you are in a position to provide as verified data, something you are happy to confirm has been verified as part of your own business process. Verified data is valuable to the individual for use downstream. The express data as verified you need to be able to make the following statements about:
- How the data was generated, what process was used within your Subscribing organisation, e.g. output from an online portal or CRM system, captured as part of a defined process by trained staff.
- When the data was generated or captured, date and time
- cross reference the range of datasets and sources into an overall view of the domain area.
- reduce the aggregated whole down to those datasets and fields that are of relevance to the individual and potentially for onward sharing and use. The essential element here is person-centric, as has already been stated.
- Segment the data attributes into three broad categories of meta, state and transactional data.
- Meta data is the static data associated with the domain, such as a bank account sort code and account number or an insurance policy number, Universal Tax Reference number etc.
- State data is a current value type data - e.g. bank balance, value of a pension policy, current preference settings or choices about a service, entitlement to something, number of points on a driving license, qualifications held, current tariffs for mobile phone, energy services etc.
- Transactional data is usually held in separate dataset as it will be regularly added to typically these are activities and events throughout ones life, e.g. bank transactions, credit card transactions, itemised call history, browsing history, measurements taken at regular intervals, location data, billing and payment history, travel history anything that is an event that occurs over time.
- Define the fields in terms of their key properties.
Making the changes
In reality there are only three cases for making changes to the existing Mydex Master schema:
- Cloning a dataset - Where the existing datasets are considered to be suitable for a particular use case, but one or more additional fields need to be added to the dataset(s).
- Adding a totally new dataset - Where a dataset (or datasets) does not currently exist within the PDS to cover the fields for a new use case or business area. Here the new dataset(s) and fields will need to be specified.
- Extending an existing dataset - Where the data covered by the specific dataset has grown as an industry or service matures and new values become part of the core records. This may include splitting out data historically concatenated that becomes available as distinct fields or it becomes recognised that parsing the data as it arrives is of benefit for onward use and analysis.
The process to be followed for all schema extensions is:
- Check and double check that the fields do not already exist within the schema. Be aware that the set of fields you want may not be in one dataset but could potentially be spread over a number of datasets. Also, the names may not be as you initially imagined due to the Mydex naming convention, so it is wise to check the field descriptions.
- We have our own checking routines and analysis but it will only delay your request if you submit a request and it fails those tests.
- Please use our online dataset request form. The form on our developer community site should be used to request any new datasets or fields which are required in the PDS schema. The can be found here.
- We plan to make it possible for developers to upload their requirements in JSON or XML format to speed up the process of extending the schema in due course.
- Mydex will review the request for the additional dataset and fields.There are a number of things we will be checking for, such as:
- That the proposed fields conform to the schema policy (see above).
- That the proposed fields do not already exist within the PDS schema.
- That there is not a better way of proportioning the proposed datasets and fields. For example, it may be that by splitting the proposed fields across a number of existing datasets rather than having them all in the same dataset as we seek to have a more general schema which is applicable to a much greater number of use cases.
- the required datasets and fields are accepted and implemented in the Mydex Master PDS schema.
- it is found that some or all of the dataset(s) or field(s) already exist within the schema.
- it is found that some or all of the dataset(s) or field(s) do not follow the naming convention.
- A formal quality assurance testing and assurance process will be conducted within our staging environment. Successful completion of the tests will result in the release into our Sandbox and Live environments.
- The new datasets and fields are now ready to be used. Assuming that the Subscriber organisation is already contracted to use the Mydex service and any new use of the fields makes no difference to the terms for the connection and planned data sharing agreement, the Subscribing organisation can go ahead and use the API to access the new datasets and fields.
- If the Subscriber organisation is new to Mydex or the use of the fields will change, the terms of the connection or the data sharing agreement currently in place the this will need to be reviewed and verified prior to the existing connection or proposed connection is approved for use on Live.
- The request for this can be carried out in parallel to steps 3, 4 and 5 above. Details can be found under the Terms for Subscribers.
- If the Subscriber organisation is new to Mydex or the use of the fields will change, the terms of the connection or the data sharing agreement currently in place the this will need to be reviewed and verified prior to the existing connection or proposed connection is approved for use on Live.
Top Tips
From the work we have done to date of many years here are some top tips when modelling data for a personal data store.
Don’t concatenate datasets
Concatenating information into a single field as is often done on typical reports and summaries but is totally unhelpful for data analysis and sharing via a personal data store.
A good example of such a case are URL’s. much of the value of analysis and insight from URL’s can be gained at the domain, subdomain and extension level. It is therefore better to store these as discrete elements within the PDS as it will speed up processing and insight.
Financial institutions often combine information in statement description fields from two or three data elements in their own systems for ease of presentation but it makes analysis difficult. It is easier to combine them later if need be. A good example is one field description containing the name of person paid, the account number paid into and the transaction reference, all data held separeately by the Subscribing organisation but concatenated for output purposes in things like statements.
Consider requesting parsing of data if you cannot do it yourself
If you have data you want to send to a personal data store but cannot parse it yourself, we can potentially do this as it arrives if there is a consistent processing rule that can be applied to the dataset. We don’t like to do it as it is time consuming and also makes verification harder but if you do not have the ability to process the output data from your systems but can define the rule for parsing it we may be able to help so please ask.
Generalise wherever possible
Where and whenever you can generalise. Don’t make your dataset organisation specific rather make it context or process specific.
An individuals life spans many years and they may collect data on the same subject from more than one place at the same time or over the years. The value is on the long term analysis as much as the short term usage during an existing relationship.
Adopt standards or defacto standards wherever you can.
Vast time, money and effort has been invested in creating standards or working towards standards, we believe it is worth using this wherever possible. Our goal is interoperability and we have focused on making it possible to expose different formats and outputs to meet different needs through our Open API’s.
We recognise that different sectors, markets and countries may have different formats and datastandards. The more we do to generalise or adopt standards the easier it is for these Subscribing organisations and markets to work with us. Mydex seeks no competitive advantage or proprietary advantage in its schema it is for the world so trying to make it specific to one Subscribing organisations needs is not something that is helpful in the long term or valuable to anyone.
Additional Information
- Mydex Community Platform - You can raise specific questions here about any aspect of Mydex CIC, its Trust Framework or Platform and in particular about our Master Schema.
- Mydex Master Schema - Our published Master Schema Datasets and Fields within them.
- Request New Data Set form - Email a request for a new PDS Dataset with your requirements after following this guide.
- Get support from Mydex CIC - use one of our support channels.
- Give us feedback on our documentation site